Table of Contents
Hybrid IT and disaster recovery: 6 things you need to know
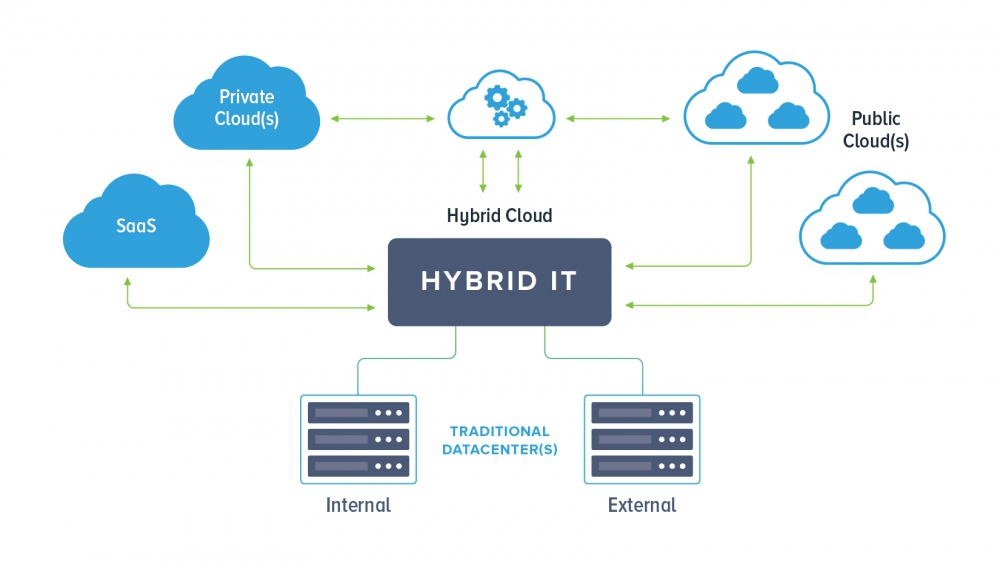
As enterprise IT continues to expand beyond the four walls of the data center, disaster recovery plans are being forced to adapt to include all infrastructure in private, public, and hybrid cloud scenarios.
“It’s double the cost, double the complexity, and double the thinking that has to go into it.”
—David Linthicum, chief cloud strategy officer at Deloitte Consulting
That’s not welcome news if you work at one of the many organizations with a woeful track record of disaster preparedness—but it’s not too late to get started.
Here’s what three experts say will help you put together a comprehensive approach to backup and recovery that takes into account modern IT’s many moving parts.
Assess your assets
One of the first and most critical steps for building a DR plan for hybrid-IT infrastructure is identifying the assets contained within each segment, said Joe Merces, CEO of Cloud Daddy, a cloud-based backup service provider. In other words, classify all business- and mission-critical applications and systems.
“The inventory of these assets is extremely important, along with the dependencies for all of those assets, in order to be not only recoverable but operational again as quickly as possible in case of a disaster.”
—Joe Merces
Once you’ve completed your inventory, it’s time to perform a risk analysis and assess the potential impacts for on-premises, private, and public cloud scenarios. Then decide what recovery point objective (RPO) and recovery time objective (RTO) methodology makes sense for each component. But don’t do this in a vacuum, Merces warned; line-of-business leaders must weigh in on setting priorities.
Cathy Miron, president and CEO of backup provider eSilo, agreed. Building a comprehensive DR plan across mixed environments can be very complex, and although it’s highly technical, it shouldn’t be done by IT alone, she said.
“Invest the time to do a proper top-down business impact assessment in partnership with key business process owners who can quantify the cost to the business of each minute of downtime in terms of lost revenue, productivity, and so on.”
—Cathy Miron
Get a view through a single pane of glass
Many companies may be tempted to incorporate their favorite legacy backup systems in their DR strategy. But they will likely find that those require costly customization and may still not meet their objectives. “The right tool for the job” should be the guiding axiom, Cloud Daddy’s Merces said.
“An enterprise may be perfectly satisfied using a specific, traditional backup product within their data center, and that incumbent product may be ingrained into that data center’s DR planning,” he explained. “But that doesn’t mean it makes sense to use, or is even practical to use, the same backup tool in backing up your infrastructure that exists within the cloud.”

Instead, enterprise IT should look to virtualization to abstract the physical layers of heterogeneous hardware and applications.
“Whether it’s legacy or your CRM or ERP system, your private cloud or your public cloud, your systems are nodes.”
—Linthicum
“Look for something that will deal with all those various kinds of environments in a very abstract layer,” Linthicum says. “If you deal with things in a very tactical way, with each of the technologies—Microsoft and IBM and even the OpenStack stuff—you’re going to drive yourself nuts.”
Instead, he said, adopt monitoring and management systems that provide disaster recovery capabilities. “They’re able to abstract from the native APIs and the legacy APIs so they can do the replication for you, but they do so through a single interface versus you having to go into the native interfaces,” Linthicum explained.
Be realistic about your data requirements
Even under the threat of a real disaster, it’s important to do triage to understand what data is essential to back up and what’s not. Backing up the wrong data can be as bad as not backing up any at all if it leaves you vulnerable during an outage.
“I think we have a tendency to overestimate and underestimate the importance of the data. I see a lot of information that should be backed up on a daily basis, such as transactional data—if you lose a day, you lose a million dollars—that isn’t getting backed up.”
—Linthicum
On the other end of the spectrum is sales information that may have five records a day that people will back up and ship offsite, he said. “You have to be realistic about what the data is, what the legal obligations are, and what’s really going to hurt you in the middle of an outage or a natural disaster.”
Test, test, test
The best disaster recovery plan is worthless if it doesn’t work in an actual disaster. As such, recovery testing is perhaps the most important component of DR for hybrid IT. But because it’s so time-consuming and resource-intensive, it’s also the element that organizations most commonly skip.
Complacency can be costly.
“When a company is faced with a disaster and unable to recover, that’s when recovery testing’s critical importance is realized—most often, too late.”
—Merces
Periodically test how your recovery plan responds to specific disasters by simulating real outages, Linthicum advises. This allows you to see how quickly and reliably your systems recover, and unearth any gaps that may have opened up due to staff or process changes since your last test.
Beware of hidden hazards
It’s a fact of IT life that the more complex your infrastructure, the more opportunities there are for things to go wrong. This is especially true when it comes to disaster recovery planning.
Most failures can be traced back to a couple of common mistakes, says Miron.
“In large enterprises with hundreds or thousands of applications and servers, I’ve seen many DR plans fall flat on their face.”
—Miron

One is that the company invests heavily in DR for a few critical systems, but neglects systems that seem less critical because of a lack of understanding around data flows and interdependencies. The other is that disaster RPOs and RTOs that are defined solely by IT might not reflect the true tolerances of the business.
Security consistency is another concern that often gets overlooked. “That’s the biggest one,” Linthicum said. “I think that we’re going to see lots of hacking where DR systems are vulnerable—maybe the prime system is protected while the secondary system is not.”
“You need to replicate security both at rest and in flight, whether you’re dealing with the private cloud, public cloud, or traditional systems.”
—Linthicum
It pays to plan
While the costs of additional hardware, software, and human labor required to execute a reliable DR plan for your hybrid environment are considerable, it’s paramount to consider the cost of not properly planning for disaster recovery in the first place.
“Whether it’s hacks or outages, to me it doesn’t really make a difference,” Linthicum said. “We’re going to see some major companies go down just because of a lack of planning in this area. I think the airlines had this rude awakening a few years ago. We’re going to see mistakes brought to the surface—data loss, systems going down, privacy issues—all these sorts of things that can rear their ugly head for not having a good DR plan.”
Need help planning an effective IT disaster recovery strategy? Contact us here or at info@esilo.com for a complimentary consultation with our CEO, Cathy Miron.